Crawl budget, czyli budżet indeksowania strony to nic innego jak ilość podstron Twojej domeny, jaką Google jest w stanie zaindeksować lub też jest to czas i ilość zapytań, jakie Googlebot zadaje twojej stronie w celu indeksacji podstron. Do głównych parametrów decydujących o crawl budget należą: crawl rate limit, czyli limit współczynnika indeksacji oraz crawl demand, czyli częstotliwość indeksacji. Ale co to właściwie oznacza?
CZYM JEST CRAWL RATE LIMIT?
W związku z tym, że Googlebot ma codziennie do przeskanowania olbrzymie ilości stron, konieczne było stworzenie wytycznych, określających czas, jaki robot Google może poświęcić danej stronie internetowej. Wszystko to w celu zapewnienia zarówno wydajności serwerów, jaki i komfortu użytkowników Internetu. Limit współczynnika indeksacji to zależność między crawl health, a limitem ustawionym w Google Search Console.
Crawl health to przede wszystkim techniczne aspekty naszej strony. Największe znaczenie ma tutaj szybkość ładowania poszczególnych podstron oraz czas odpowiedzi serwera i jego wydajność. Im nasza strona ładuje się szybciej, tym jest szansa, że Googlebot zaindeksuje większą ilość stron przy jednorazowej wizycie. Informacji na ten temat możemy szukać w Google Search Console w zakładce ‘Starsze narzędzia i raporty’, gdzie wybieramy opcję ‘Statystyki indeksowania’.
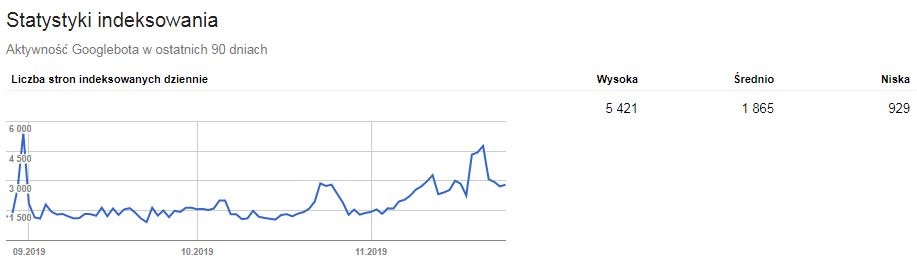
Wówczas mamy do wglądu wykres przedstawiający liczbę stron indeksowania dziennie. Możemy sprawdzić aktywność robota Google w ostatnich 90 dniach i wyciągnąć odpowiednie wnioski, a także upewnić się, że Googlebot nie napotyka na naszej stronie żadnych problemów. Warto monitorować statystyki indeksowania oraz zapisywać je w celu śledzenia indeksacji.
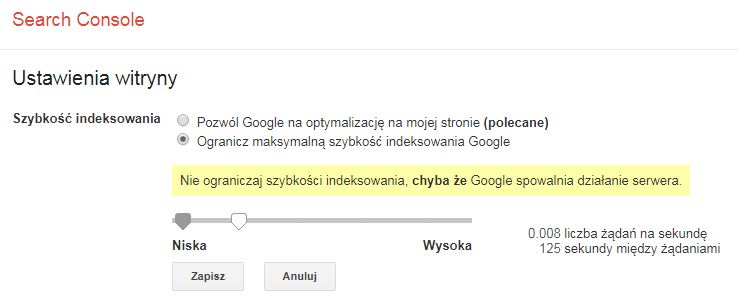
Googlebot, korzystając z zaawansowanych algorytmów, stara się indeksować optymalną ilość podstron. Jeśli jednak wysyła zbyt dużą ilość żądań na sekundę i spowalnia pracę serwera, istnieje możliwość ograniczenia szybkości indeksowania witryny. W tym celu należy skorzystać z narzędzia oferowanego przez Google i w panelu Google Search Console w zakładce ‘Starsze narzędzia i raporty’ wybrać opcję ‘Dowiedz się więcej’. Wówczas pojawi się okno pomocy z opisem dostępnych narzędzi, wśród których będą ‘Ustawienia szybkości indeksowania’ lub też możemy otworzyć bezpośrednio stronę ustawień szybkości indeksowania – https://www.google.com/webmasters/tools/settings i skorzystać z dostępnych funkcji.
CZĘSTOTLIWOŚĆ INDEKSACJI
Tutaj kluczowe znaczenie ma ‘Popularity’, czyli popularność naszej strony oraz ‘Staleness’, czyli jej ‘świeżość’, które możemy określić jako atrakcyjność strony lub sklepu internetowego dla robota Google. Częstotliwość indeksacji to czynnik jakościowy. Im więcej odwiedzin na naszej stronie Internautów, tym Googlebot również chętniej nas odwiedza i dokonuje indeksacji strony. Dlatego niezwykle ważne jest tworzenie produktów pod użytkownika, zachęcając go do wizyt i przekazując wartościowe, unikalne i uaktualniane na bieżąco treści. Istotny jest ciekawy content i jego wysoka jakość. Niestety nie mamy możliwości zmienić tego, jak często Googlebot indeksuje naszą witrynę, ale możemy poprosić o indeksowanie, korzystając z odpowiedniej opcji w Google Search Console. Aby przesłać url do indeksu Google wystarczy sprawdzić dany adres strony i kliknąć prośbę o zaindeksowanie.
CZY POWINNIŚMY MARTWIĆ SIĘ O CRAWL BUDGET?
W przypadku domen o niewielkiej ilości podstron zazwyczaj Googlebot nie ma problemu z indeksowaniem stron. Problem pojawia się w przypadku rozbudowanych sklepów internetowych, generujących tysiące podstron. Więcej na ten temat możemy znaleźć na oficjalnym blogu Google Webmaster.
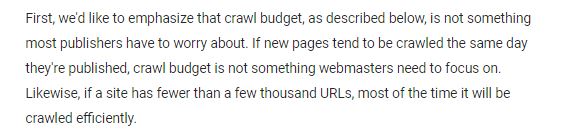
Źródło: https://webmasters.googleblog.com/2017/01/what-crawl-budget-means-for-googlebot.htm
CZY GOOGLEBOT INDEKSUJE WSZYSTKIE NASZE PODSTRONY?
Aby poznać odpowiedź na to pytanie, warto skorzystać z wyszukiwarki Google i do okna wyszukiwań wpisać nazwę naszej domeny, poprzedzając zapis parametrem ‘site:’.
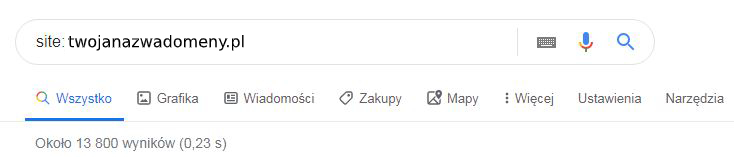
Wówczas powyżej wyników wyszukiwania pojawia się informacja o przybliżonej ilości adresów url zaindeksowanych przez Google. Znając swoją stronę lub sklep internetowy, możemy ocenić, czy jest to liczba, która odpowiada ilości podstron, zarówno kategorii, jak i produktów, jakie posiadamy na stronie.
Warto również sprawdzić, czy wyniki, jakie otrzymaliśmy są tymi, których byśmy oczekiwali. Czy wśród nich nie ma na przykład stron filtrowania, rejestracji czy logowania. Takie strony nie powinny znaleźć się w takich wynikach wyszukiwania.
CRAWL BUDGET A STAN STRONY W GOOGLE SEARCH CONSOLE
W celu dokonania analizy stron indeksowanych przez Google warto również zapoznać się z opcją ‘Stan’, dostępną w panelu Google Search Console. Możemy tutaj sprawdzić, czy są jakieś podstrony, które powodują błędy lub też, czy posiadamy podstrony, wobec których pojawia się komunikat z ostrzeżeniem. Mogą być to strony, które na przykład są zaindeksowane, ale jednocześnie blokowane przez plik robots.txt. Warto przeanalizować powód tego i rozważyć ich usunięcie z indeksu Google.
Jednak najważniejszą opcją, jaką tutaj znajdziemy jest liczba stron określona jako ‘Prawidłowe’ oraz liczba stron określona jako ‘Wykluczone’.
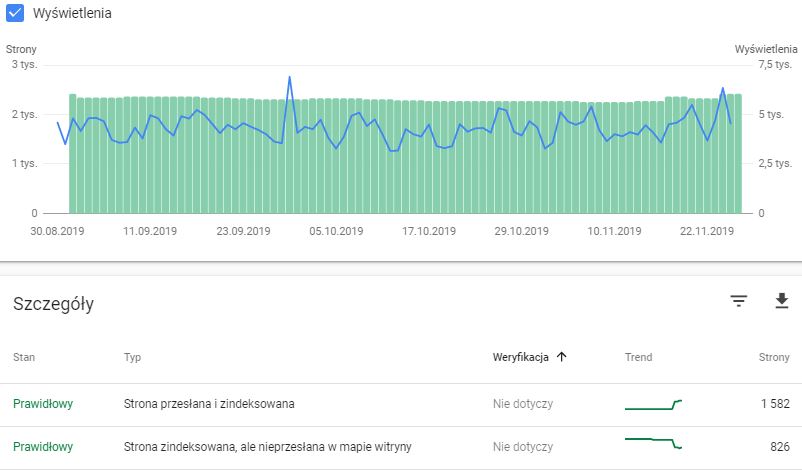
Możemy sprawdzić, czy strona zaindeksowana znajduje się w mapie witryny oraz jaki jest trend indeksacji. Natomiast w opcji stron wykluczonych mamy możliwość sprawdzenia, jaka jest przyczyna wykluczenia. Czy jest ona zgodna z naszymi oczekiwaniami. I tu pojawia się pytanie: jakiego typu strony powinny się tutaj znaleźć?
JAK DOKONAĆ OPTYMALIZACJI CRAWL BUDGET?
Dokonując optymalizacji crawl budget należy dokonać analizy, jakie podstrony naszej domeny są dla nas wartościowe, a jakie nie powinny znaleźć się w wynikach indeksowania.
Nawigacja fasetowa oraz adresy url z parametrami
Szczególnie w przypadku sklepów internetowych warto sprawdzić, w jaki sposób działa zaimplementowana na naszej stronie nawigacja fasetowa oraz opcje filtrów produktów. Jest to temat szczególnie istotny i jak się okazuje bardzo często lekceważony, a trzeba wiedzieć, że źle stworzona nawigacja fasetowa,czyli opcje filtrowania, przyczyniają się do generowanie dużej liczby adresów url, które trafiają do indeksu Google, tworząc duplikację treści i ograniczając zasoby crawl budget. Może się okazać, że dynamicznie tworzone adresy stron z tak zwanymi parametrami, indeksowane przez Google, wcale nie generują ruchu, a jedynie osłabiają jakość naszego sklepu. Warto wówczas wyposażyć takie adresy url w odpowiednie meta tagi dla sklepu internetowego i w przypadku takich podstron wdrożyć meta robots z dyrektywą “noindex”.
Duplikacja treści i thin content
Bywa, że z duplikacją treści mamy do czynienia nie tylko w przypadku nawigacji fasetowej, ale również w przypadku pojedynczych adresów stron. Należy pamiętać, że duplicate content może znacząco osłabić naszą stronę, a także ograniczyć widoczność strony w Google, który preferuje unikalne treści. Ważne jest, aby przedstawione na stronie treści były wyczerpujące dla danego tematu i wartościowe dla potencjalnego użytkownika, który odwiedzi naszą stronę.
Nie należy indeksować stron słabej jakości oraz o niewielkiej ilości treści.
Pozorne błędy 404
Pojawiają się wówczas gdy serwer zamiast kodu 404, zwraca kod odpowiedzi 200 na stronie, która nie istnieje. Na szczęście jeśli takie strony pojawiają się w obrębie naszej witryny, możemy je znaleźć w opcji ‘Błąd’ dla zakładki ‘Stan’ w Google Search Console. Zobaczymy wówczas komunikat o następującej treści ‘Przesłany adres URL wydaje się zgłaszać pozorny błąd 404’.
META ROBOTS A BUDŻET INDEKSOWANIA
W celu dokonania selekcji stron indeksowanych musimy wyposażyć jej w meta tag robots, który najczęściej w takim przypadku będzie wyglądał tak:
meta name="robots" content="noindex"
Powyższy kod należy wdrożyć w sekcję head strony. Warto go zaimplementować dla adresów url generowanych za pomocą filtrów produktów, czy też stron zawierających duplicate lub thin content. Dzięki temu crawl budget naszej strony będzie bardziej efektywny.
JAK PRAWIDŁOWO STWORZYĆ SITEMAPĘ?
W celu nakierowania robotów Google na indeksację ważne jest stworzenie mapy witryny oraz wdrożenie jej do panelu Google Search Console. Ułatwi to dotarcie do wartościowych podstron i zapewni sprawny crawl budget. Istotne jest, aby adresy, które znajdą się w sitemapie, były adresami zwracającymi kod odpowiedzi serwera 200.
Należy unikać w mapie witryny adresów url zawierających meta robots z contentem “noindex”, a także stron zwracających kody odpowiedzi serwera inne niż 200, stron paginacji i stron blokowanych przez plik robots.txt. Błędna implementacja mapy i jej błędna zawartość mogą prowadzić do powstania problemów ze skanowaniem strony oraz obniżyć wydajność crawl budget.
Warto również stworzyć indeks mapy witryny, w którym umieścimy kilka mniejszych sitemap na przykład z podziałem na kategorie lub produkty. Ułatwi nam to poruszanie się po mapie witryny i ewentualne wychwytywanie błędów.
SZTUKA TWORZENIA
Ważne jest uwzględnienie wszystkich wymienionych wytycznych, aby crawl budget zapewniał nam indeksowanie maksymalnie dużej liczby stron, szczególnie tych wartościowych, które zapewnią nam ruch, a przede wszystkim dochód. Nie sztuką jest bowiem stworzenie strony lub też sklepu internetowego. Sztuką jest stworzenie interesującego produktu i usługi o wysokiej jakości i atrakcyjności zarówno dla robota Google, jak i potencjalnego użytkownika.
Autor: Sylwia Woźniak, Technical SEO Specialist